
Chapter 07: 清洗與限制 (Filter, Limit, Dedupe)
在自動化的實戰中,資料的品質決定了工作流的穩定度,如果進來的資料帶有瑕疵(髒資料),那整個流程很快就會癱瘓。這章我們要聊聊如何透過三種核心 Node,在資料進入核心邏輯前做好門禁管制,確保每一筆 Data Item 都是乾淨且必要的。
學習目標 (Goal)
搞懂 Filter (精準守門員):篩選出必要的關鍵資料。
掌握 Limit (限流保險絲):防止大量資料灌爆工作流。
理解 Remove Duplicates (髒資料剋星):移除重複項確保資料唯一性。
掌握自動化流程中的「優化意識」與資源配置。
核心觀念 (Concepts)
Filter:精準的守門員
Filter 不只是簡單的篩選,它是你的「標準檢驗局」。透過多重條件的組合,你可以確保只有符合業務邏輯(例如:訂單狀態必須是 paid 且金額大於 0)的 Item 才能通過。
Limit:工作流的保險絲
想像你要去 API 撈資料,結果對方一口氣噴回 5,000 筆,這會讓你的伺服器瞬間壓力爆表。Limit 的作用就是「限流量」,在開發與測試階段,我們通常會限縮在 1 到 5 筆,確定路走通了再放開。
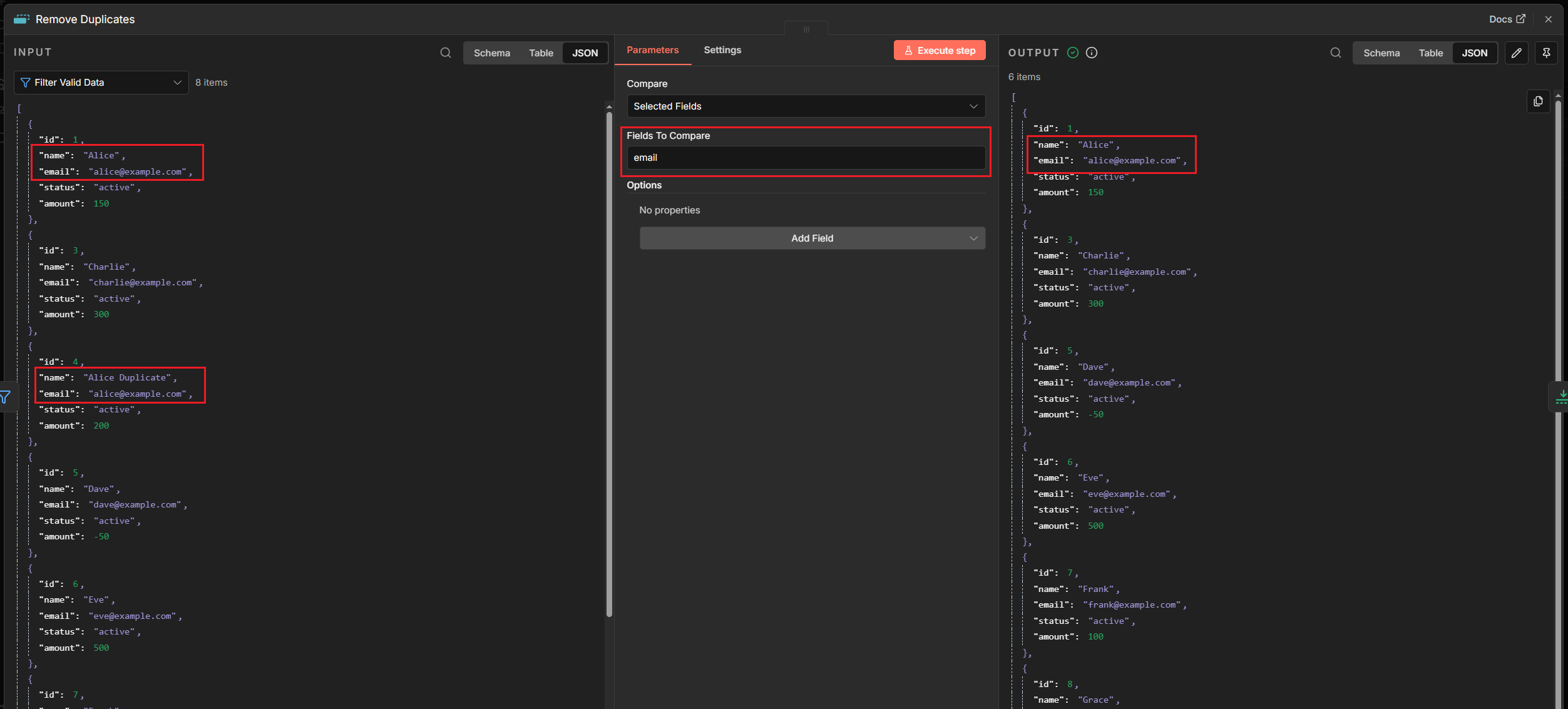
Remove Duplicates:髒資料的剋星
重複的資料是自動化的噩夢。重複的 Email 可能會讓客戶收到兩次騷擾信,重複的訂單編號可能導致重複出貨。這時候我們需要一個唯一鍵(Unique Key)來剔除重複項。
節點配置 (Node Setup)
Filter Node
- Conditions: 選擇你要比對的 Data Type(String, Number, Date 等)。
- Logic: 搭配 AND/OR 進行複合式判斷。
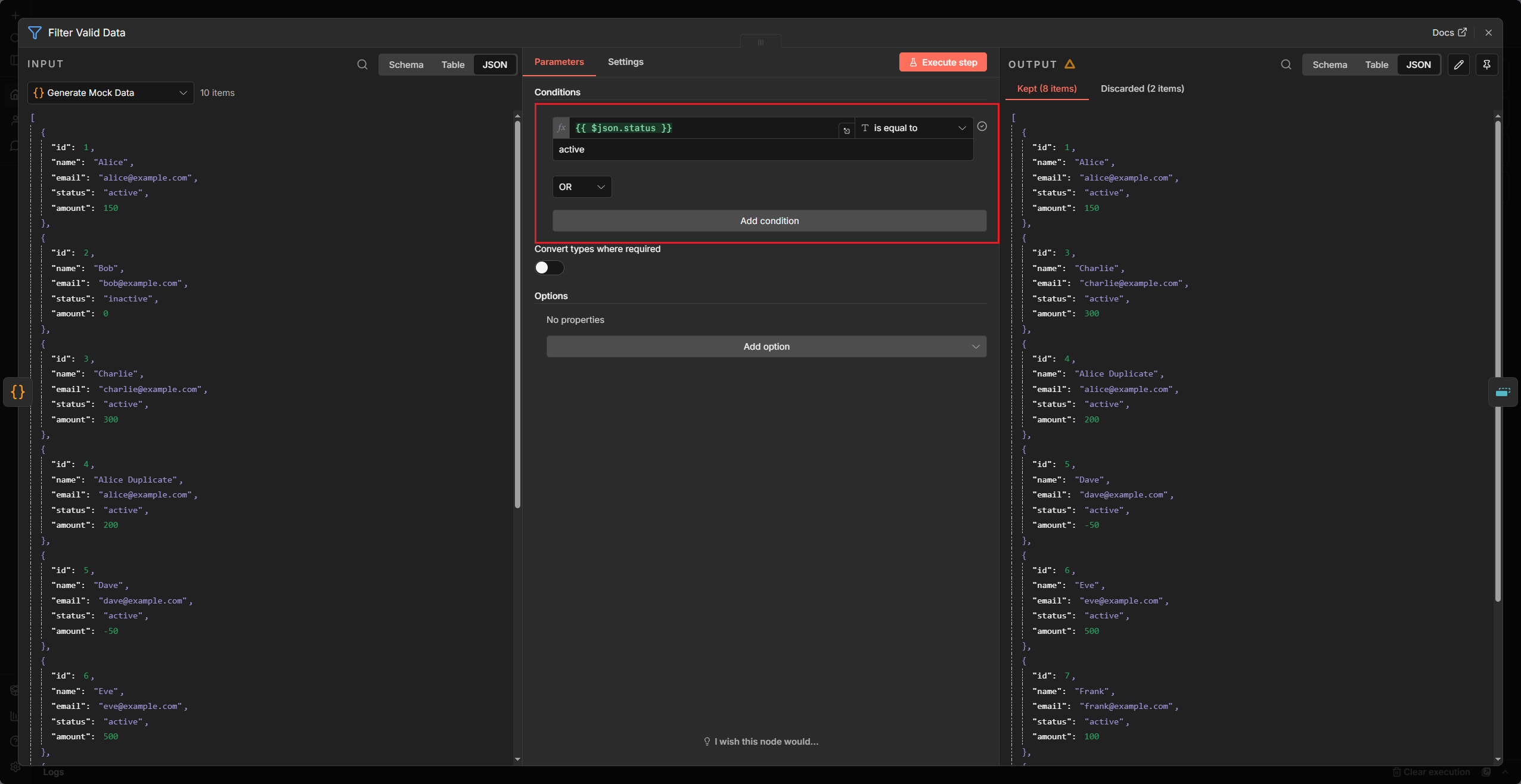
NOTE
搭配多種條件組合,透過 AND、OR
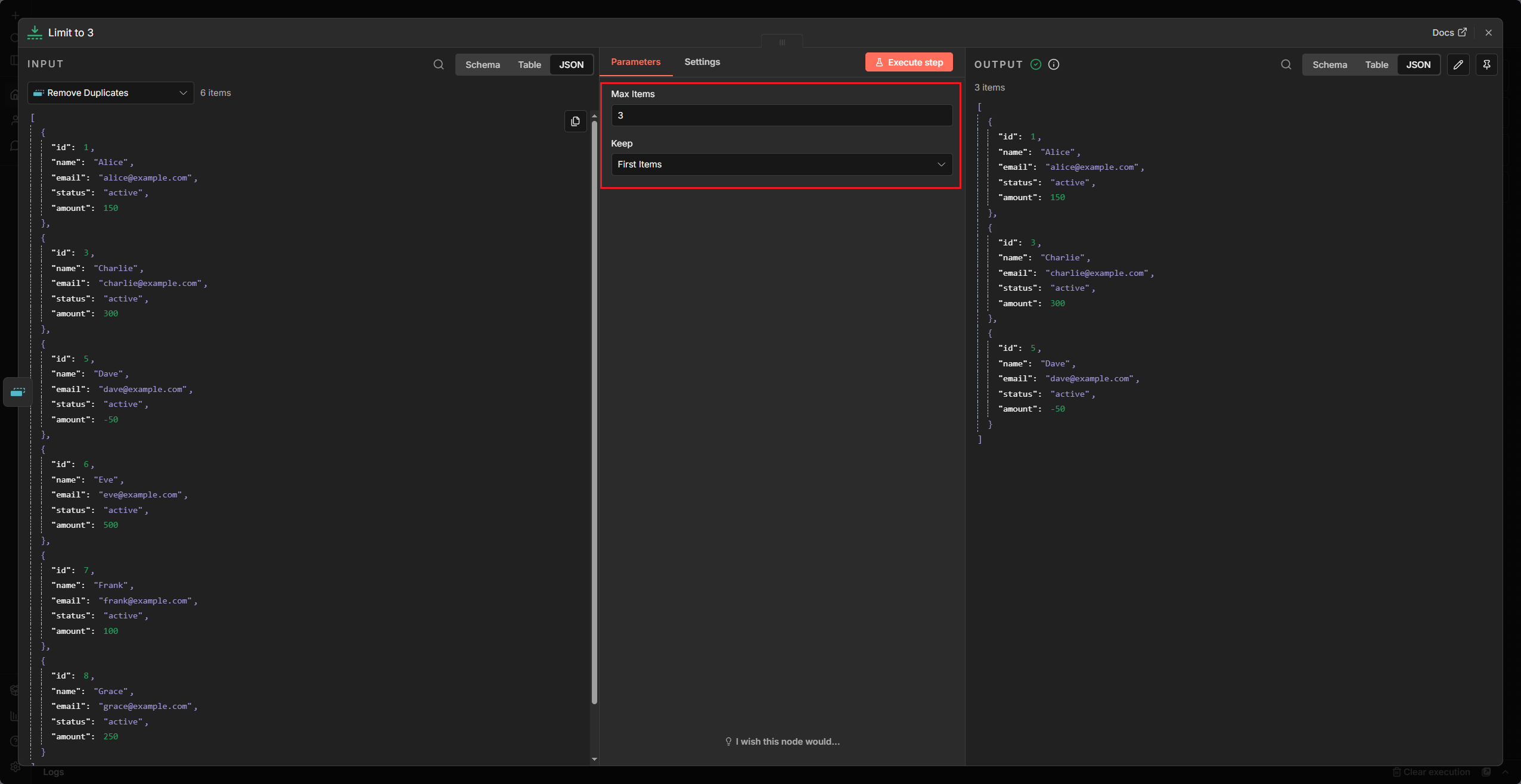
Limit Node
- Max Items: 填入你想保留的最大 Item 數量。
- Keep: 選擇要保留
First(前面)還是Last(後面)的 Item。
Remove Duplicates Node
- Fields to Compare: 勾選作為判斷標準的欄位名(如
email)。
專業操作 (Action)
Step 1: 資料篩選與清洗
試著模擬一個場景:使用 Code Node 產生 10 筆原始資料,其中包含無效資料(狀態非 active 或金額 <= 0),以及 Email 重複的資料。
- 使用 Filter Node 篩選出
status等於active且amount> 0 的有效 Item。 - 接上 Remove Duplicates Node,使用
email作為 Unique Key 移除重複的名單。 - 在最後輸出的地方接上 Limit Node,限制只顯示前 3 筆結果。
實戰挑戰 (Challenge)
- 多重條件練習:在 Filter 節點中嘗試加入 OR 條件,例如「金額 > 1000 OR 狀態為 VIP」。
- 去重策略實驗:試著用不同的 Fields 作為去重標準(例如組合
name與email),觀察結果差異。 - 限流保護:模擬從外部 API 抓取 100 筆資料,並用 Limit 節點保護下游系統,只處理前 10 筆。
TIP
真正的自動化大師,永遠不會相信原始資料是 100% 乾淨的。在進入核心業務邏輯(如寄信、存資料庫)之前,務必先經過這三道門禁處理。