在真實的自動化場景中,資料不全是 JSON。有時候你需要從某個新聞網站爬下 HTML 片段,有時候舊型系統會噴給你一堆 XML 標籤,甚至你處理完資料後需要產出一份漂亮的 Markdown 報告發送到 Slack。這章教你如何穿梭在這些不同的語言格式之間。
學習目標 (Goal)
搞懂 HTML Extract (網頁爬蟲入門):從雜亂的網頁源碼中精準提取資料。
掌握 Markdown (專業輸出標準):將資料轉化為內容平台通用的美觀格式。
掌握 XML (舊系統相容):學會如何與傳統企業系統的資料格式對接。
建立跨系統資料「橋接」的技術深度。
核心觀念 (Concepts)
HTML Extract:網頁爬蟲入門
如果你想要監控某家電商的價格,或是追蹤某個網站的更新,這個 Node 就是你的「眼睛」。它能幫你從雜亂的網頁原始碼中,精準提取出你感興趣的 Item。
Markdown:專業輸出標準
處理完資料後,發送訊息時帶上格式(如粗體、表格)是架構師的修養。Markdown 是目前各大平台(Telegram, Discord, Slack, Notion)通用的格式,學會互轉非常超值。
XML:與舊系統握手
雖然 JSON 已經統治世界,但許多傳統企業的核心系統依然在使用 XML。學會將 XML 快速轉化為 n8n 易於處理的 Item 結構,能大幅提升你的整合能力。
節點配置 (Node Setup)
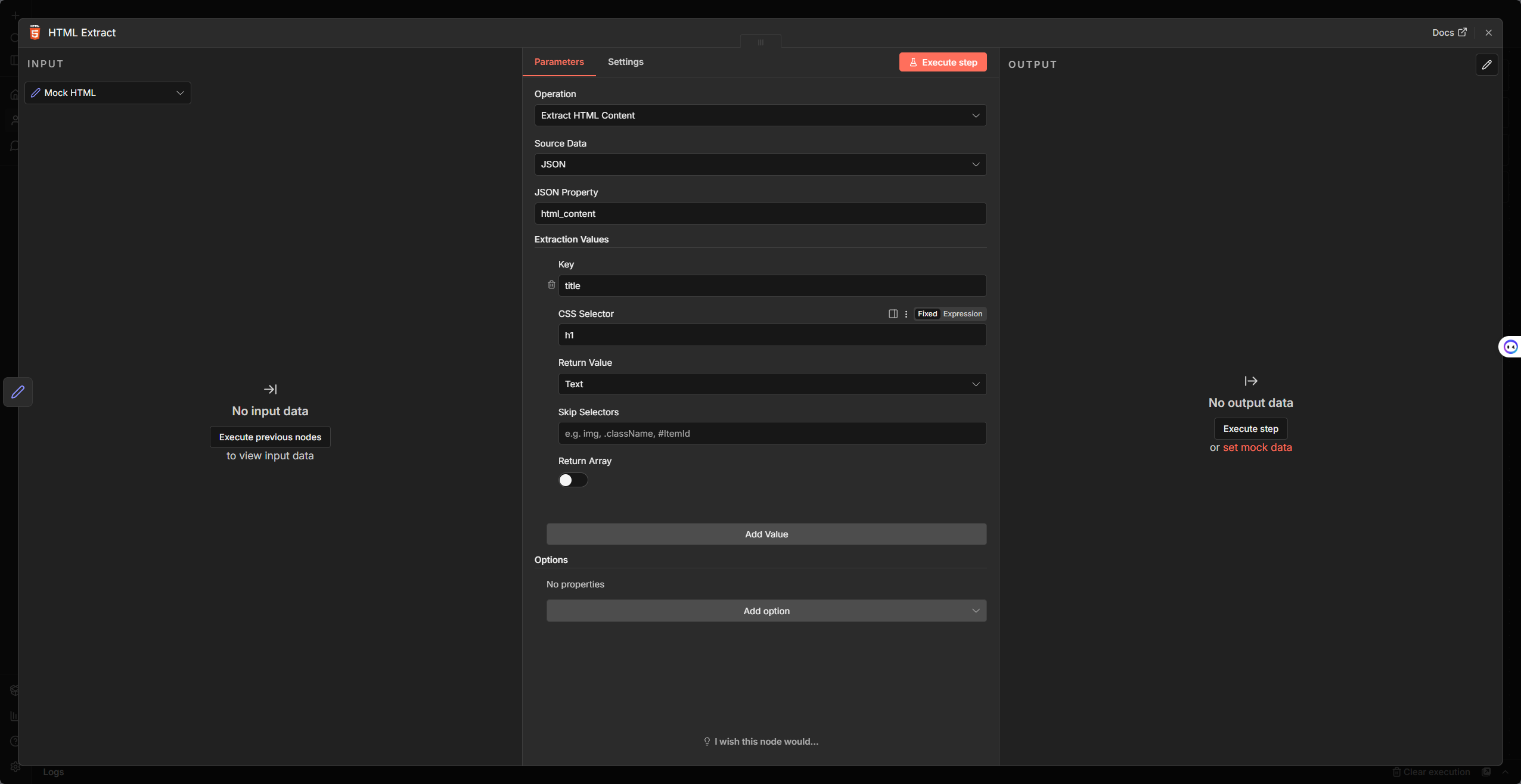
HTML Node(Extract HTML Content)
n8n 內建的 HTML 節點(自 0.213 起取代舊版 HTML Extract),操作選「Extract HTML Content」時:
* Source Data:選 JSON 時指定 JSON Property(如 html_content)為 HTML 來源欄位;選 Binary 時則指定 Input Binary Field(來源為 .html 檔)。
Extraction Values:使用 CSS Selector(如
h1或.product-list),Return Value 選Text(元素文字)或Attribute(須指定屬性名,如class)。可設定 Key 作為輸出欄位名稱。Options:Clean Up Text 可移除多餘空白與換行;Trim Values 可去除首尾空格;Return Array 可將多個提取值以陣列回傳。
同一節點尚有 Convert to HTML Table(將資料轉為 HTML 表格)、Generate HTML template(用 Expression 與 HTML 產生模板)等操作,可依需求選用。
CAUTION
使用 Generate HTML template 時,若將未經信任的輸入直接嵌入模板,可能產生 XSS(跨站腳本)風險。務必對外部輸入進行過濾或跳脫。
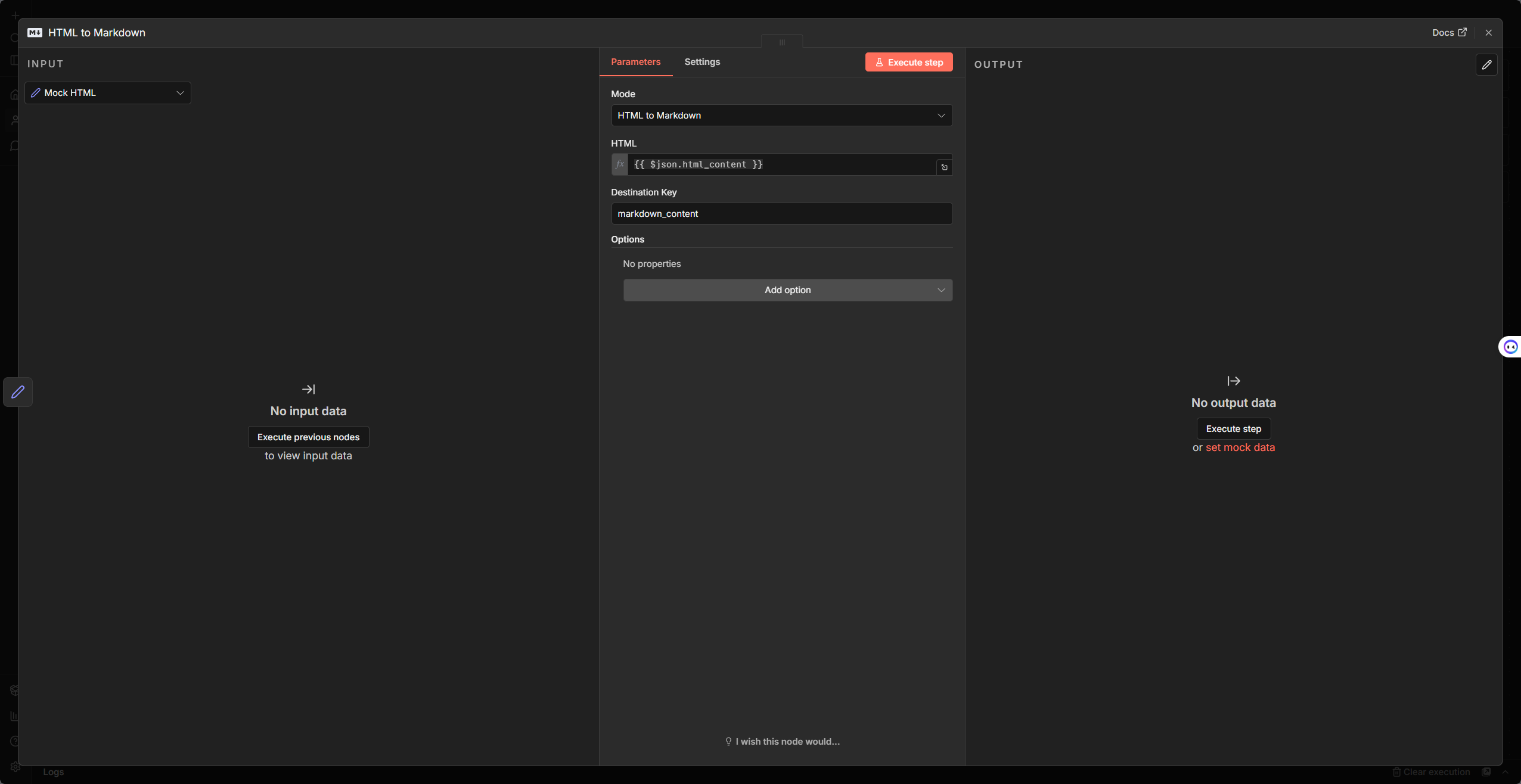
Markdown Node
Mode:選
HTML to Markdown(將網頁抓回來的 HTML 轉成 Markdown)或Markdown to HTML。HTML / Markdown:輸入要轉換的欄位(可用 Expression 如
{{ $json.html_content }})。欄位名稱會依 Mode 切換。Destination Key:轉換結果要寫入的欄位名稱。支援 Dot Notation(如
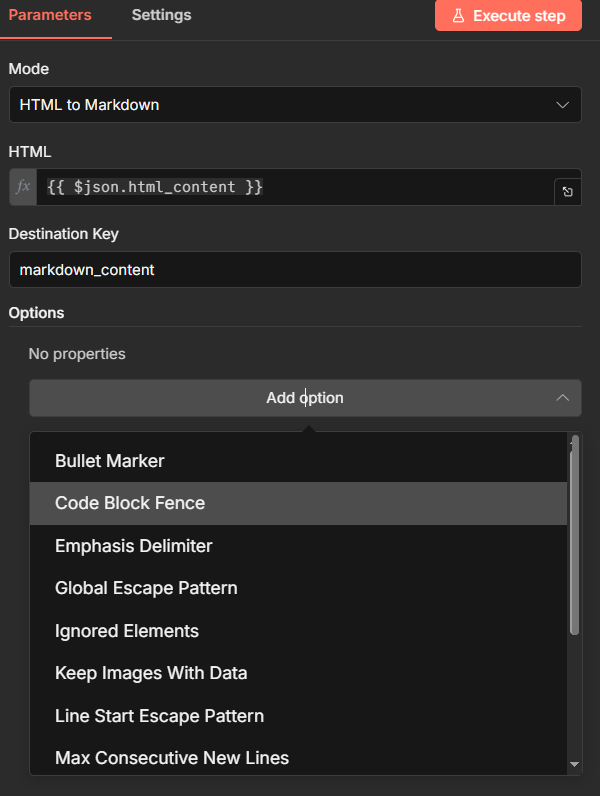
level1.level2.newKey)寫入巢狀結構。Node options:可微調輸出格式,例如 HTML to Markdown 的 Bullet Marker、Code Block Fence;Markdown to HTML 的 Tables Support、Strikethrough 等。
XML Node
Mode:選
XML to JSON(將 XML 轉為 n8n 易處理的 JSON)或JSON to XML(反向轉換)。Property Name:指定哪個 JSON 欄位含有要轉換的 XML 字串(如
xml_data)。Character Key / Attribute Key:轉換後 JSON 中,文字內容預設以
_前綴存取,屬性以$前綴存取。XML to JSON options:Trim 可去除文字首尾空白;Normalize Tags 可將標籤轉小寫;Explicit Array 可強制子節點以陣列呈現;Merge Attributes 可將屬性與子元素合併。轉換後若巢狀過深,可搭配 Edit Fields 或 Split Out 攤平。
NOTE
若 XML 在 binary 檔(如
.xml)中,需先用 Extract from File 節點轉成文字再送入 XML 節點。
專業操作 (Action)
Step 1: 網頁資料提取與轉碼
試著模擬一個小爬蟲的任務:
- 假設你有一個包含 HTML 片段的變數,內容是
<h1>新聞標題</h1><p>內容...</p>。 - 使用 HTML 節點(操作選 Extract HTML Content)提取出
h1的文字作為標題。 - 利用 Markdown 節點 將整段內容轉換為 Markdown 格式,準備發信使用。
實戰挑戰 (Challenge)
- CSS Selector 練習:找一個你常用的網站(如氣象局或技術論壇),嘗試寫出能精準抓取「最新標題」的 CSS Selector。
- XML 結構解析:找一個公開的 RSS Feed(通常是 XML 格式),練習用 XML 節點將其轉為 n8n 可讀的 JSON。
- 多格式報告產出:將一組 JSON 資料(包含標題、內容、時間),批次轉化為一段漂亮的 Markdown 表格。
IMPORTANT
進行網頁抓取(Web Scraping)時,務必遵守「網路規則」:檢查 robots.txt 並避免超頻存取,這不僅是技術問題,更是工程師的職業操守。
TIP
很多時候 XML 轉換後會產生嵌套過深的陣列,這時候記得回頭用我們上一章學到的 Edit Fields 或接下來的 Split Out 節點來攤平資料。
範例 (Example)
可依序匯入 chapter-09-format-converters-part1.json、part2 進行分段練習;下方為完整工作流(HTML 提取+HTML 轉 Markdown+XML 轉 JSON)。