這不是簡單的加法。當一條流程要同時讀取「資料庫名單」與「API 客戶資料」時,你必須精準告訴系統:這兩坨資料是要接在一起,還是要互相對位?
當我們的自動化流程從「單線道」升級為「多線道」時,首先面臨的挑戰就是:如何讓分散的資料流在某個節點重新交會?Merge 節點就是這個十字路口的交通警察。
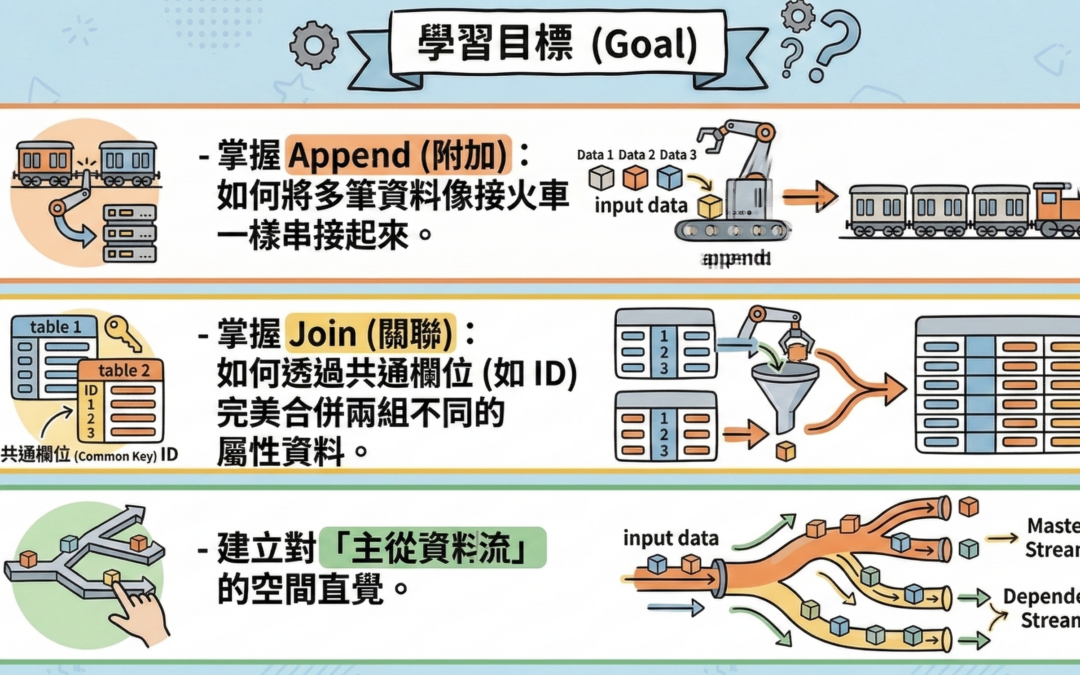
學習目標 (Goal)
- 掌握 Append (附加):如何將多筆資料像接火車一樣串接起來。
- 掌握 Join (關聯):如何透過共通欄位 (如 ID) 完美合併兩組不同的屬性資料。
- 建立對「主從資料流」的空間直覺。
核心觀念 (Concepts)
為什麼需要 Merge?
在真實業務情境中,資料往往散落在不同地方。例如:行銷系統有客戶的 Email,而電商系統有客戶的 購買紀錄。想發送客製化信件,你就得先把兩邊的資訊「合併」成一個完整的 Item。
Merge 的兩大核心模式
雖然 Merge 節點有四種主要模式,但最關鍵的是這兩個:
Append (附加 / 堆疊)
- 概念:垂直相加。把 Input 2 的資料接在 Input 1 後面。
- 情境:從兩個不同的來源抓取「潛在名單」,最後合併成一個長長的清單進行群發。10 筆 + 15 筆 = 25 筆。
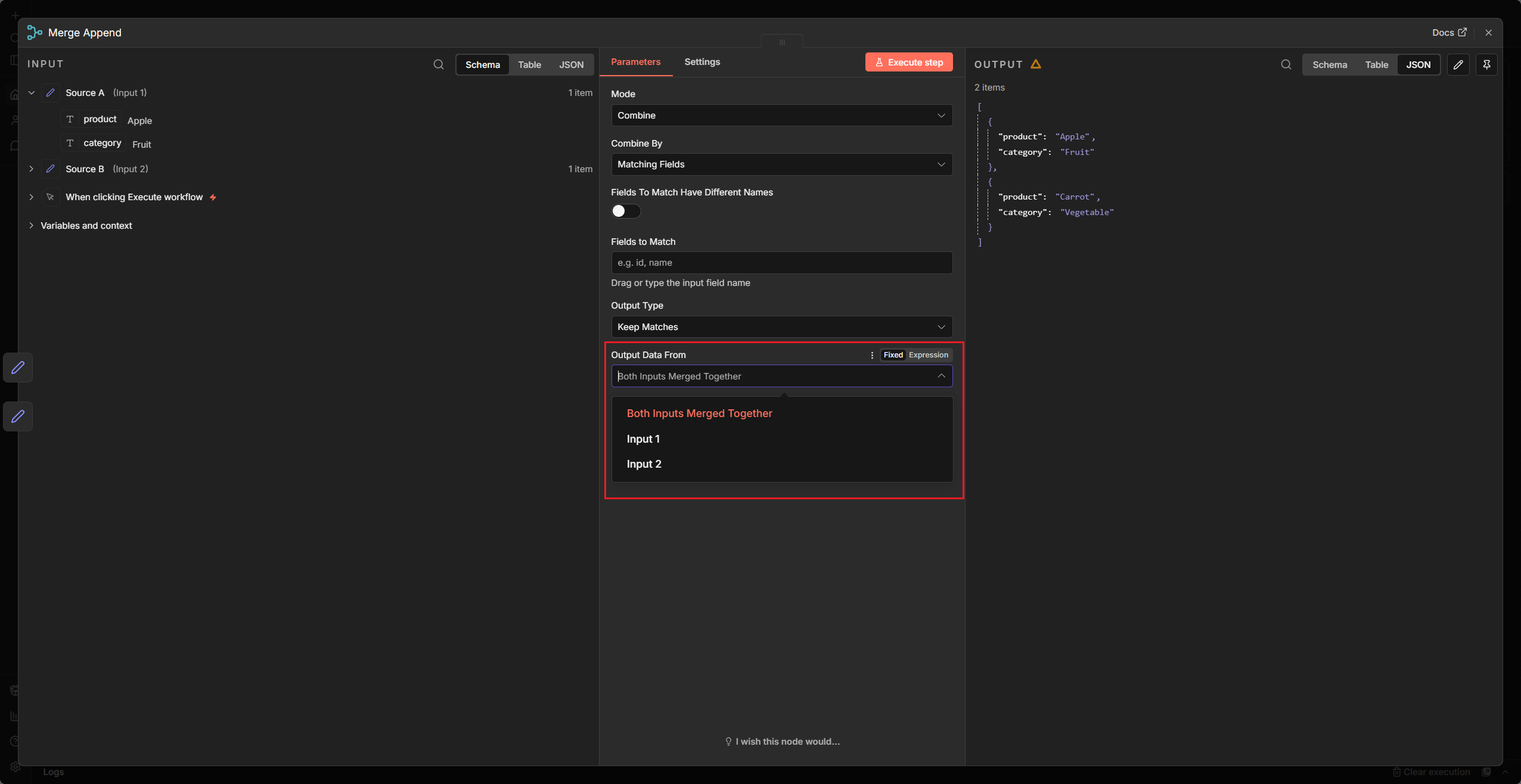
Combine -> Matching Fields (關聯合併 / Join)
- 概念:水平擴充。根據一個共同的 Key (如
Customer_ID),把 Input 2 的欄位補充到 Input 1 上。 - 情境:名單 A 有
[Name, Email, ID],名單 B 有[ID, Phone, Address]。透過比對 ID,產出[Name, Email, Phone, Address, ID]的完整清單。
- 概念:水平擴充。根據一個共同的 Key (如
TIP
主線優先原則:在 n8n 中,連線到 Merge 節點上方的 Input 1 通常被視為主體資料,而下方的 Input 2 則是補充資料。在進行 Join (Matching Fields) 時,決定誰是 Input 1 常常會影響合併失敗時(找不到對應資料)的結果處理!
節點配置 (Node Setup)
Merge Node
- Mode:選擇整合邏輯。
- Append:垂直串接。將 Input 2 的 Item 接在 Input 1 後面,輸出順序為 Input 1 全數 → Input 2 全數。可設定 Number of Inputs(n8n 1.49.0+ 支援超過 2 個輸入)。
- Combine:水平合併。選 Combine By 決定合併方式:
- Matching Fields(Merge By Fields):依欄位值比對。設定 Fields to Match(Input 1 欄位 ↔ Input 2 欄位)。Output Type 決定合併策略:Keep Matches(Inner Join,預設)、Enrich Input 1(Left Join)、Enrich Input 2(Right Join)、Keep Everything(Outer Join)、Keep Non-Matches(僅輸出無對應的 Item)。
- Position:依順序合併,Index 0 對 Index 0、Index 1 對 Index 1。可開啟 Include Any Unpaired Items 保留未配對的 Item。
- All Possible Combinations:產出所有可能組合(笛卡爾積)。
- SQL Query(n8n 1.49.0+):自訂 SQL 合併邏輯,如
SELECT * FROM input1 LEFT JOIN input2 ON input1.name = input2.id。 - Choose Branch:僅保留其中一個輸入(Input 1、Input 2 或空 Item),用於流程分支選擇。
- Options(Combine 模式):Multiple Matches 可選 Include First Match Only 或 Include All Matches;Clash Handling 可選 Shallow Merge(僅頂層)或 Deep Merge(含巢狀物件),預設 Input 2 覆蓋同名欄位。
NOTE
當兩輸入 Item 數量不同時,Input 1 的數量為主;Input 2 多出的 Item 不會被處理。
NOTE
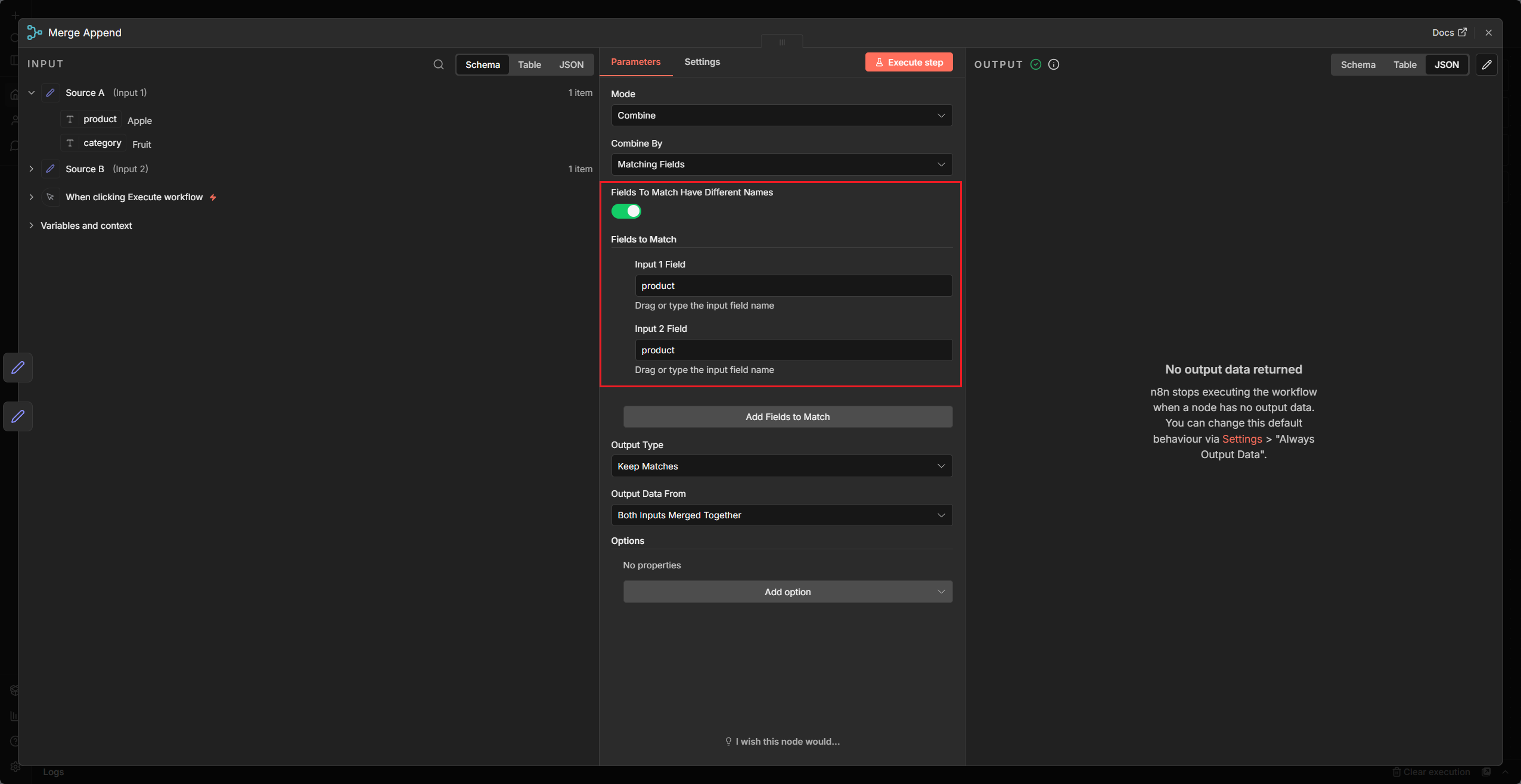
[擷圖情境:展示 Merge 節點設定為 Combine -> Matching Fields 模式。在 Fields to Match 區塊中,Input 1 Field 與 Input 2 Field 分別填入要比對的欄位名稱(例如兩邊皆填 user_id,表示依 user_id 值配對;若欄位名不同,可填 Input 1 的 user_id 對應 Input 2 的 customer_id)]
專業操作 (Action)
Step 1: 體驗 Append (附加) 的威力
首先,我們會模擬兩條來源線,分別產生兩組不同的水果清單,並用 Append 將它們變成一長串。
- 準備兩組 mock(Source A1/A2、Source B1/B2 各 2 筆)以輸出不同的 Item。
- 將 Source A 組匯入
Merge的 Input 1,Source B 組匯入 Input 2,選擇Append。 - 觀察 Output:原本各 2 個 Item(Source A1/A2、Source B1/B2 各兩筆),合併後變成 4 個 Item。
Step 2: 體驗 Join (關聯合併) 的精準比對
接下來,這才是精華。我們準備了「使用者基本資料」跟「使用者購買等級」,我們將透過 user_id 將這兩組完全不同的資料縫合起來。
Input 1準備包含user_id與name的資料。Input 2準備包含user_id與tier(如 VIP) 的資料。- 在
Merge節點選擇Combine->Matching Fields,設定 Fields to Match。 - 在 Input 1 Field 與 Input 2 Field 皆填入
user_id。 - 觀察 Output:兩個欄位被完美拼成了一個包含 name 與 tier 的完整 Item。
實戰挑戰 (Challenge)
- 處理缺漏資料:若 Combine 時 Input 1 的
user_id在 Input 2 找不到對應,預設 Keep Matches(Inner Join)會捨棄該 Item。試著改為 Enrich Input 1(Left Join)或 Keep Everything(Outer Join),觀察有無對應的 Item 是否都被保留。亦可試 Keep Non-Matches,僅輸出無對應的 Item,適合用來找出「缺漏資料」。 - 多個條件判定:嘗試加入兩個條件來進行 Join 比對,例如必須同時符合
user_id與company_id才算同一筆資料。 - 資料庫跨表查詢:試著把 Input 1 接上真實的資料庫 A,Input 2 接上 HTTP Request (呼叫某個 API),感受異質系統合併的威力。
範例 (Example)
範例:Append 模式 (簡單串接)
範例:Join 模式 (欄位對接)
可匯入 chapter-11-merge-part2.json 進行練習。把有著共同 user_id 的兩組不同資料水平縫合。