最難的自動化不是「把 A 傳到 B」,而是「只把 A 中『更新的部分』傳到 B,不要重複傳送」。這就是資料同步的心法。
當你要維持兩個系統(例如:你的內部資料庫與 Mailchimp 電子報系統)名單一致時,你絕對不會想每天早上把 10,000 筆資料全部刪掉重傳。Compare Datasets 節點就是為了解決這種「差異同步」而生的神器。
學習目標 (Goal)
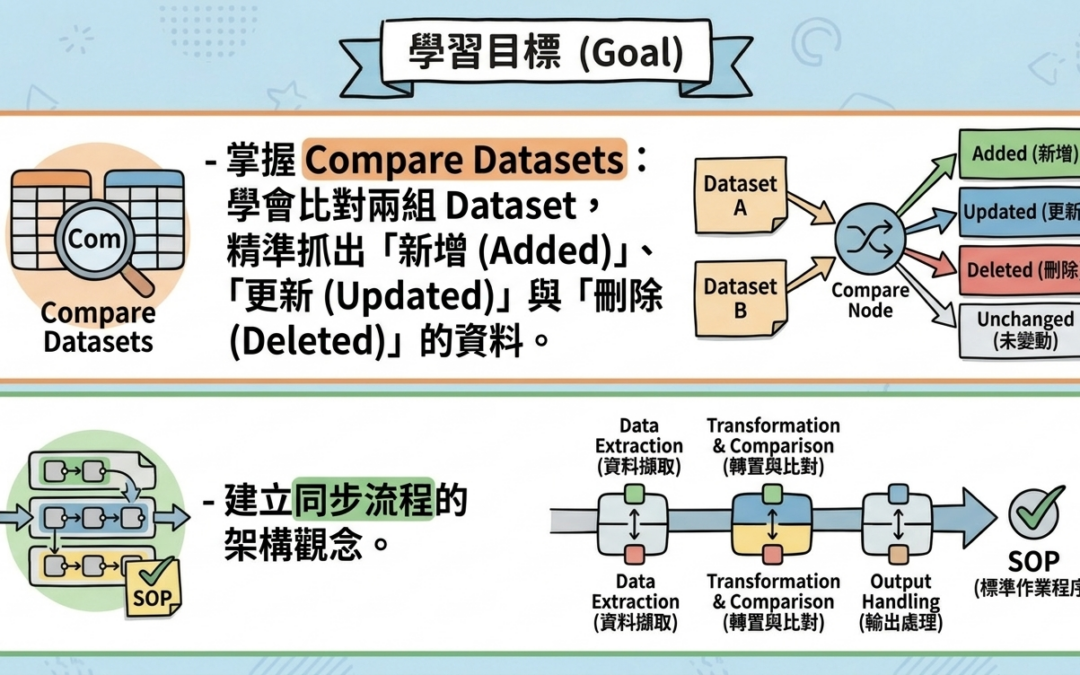
- 掌握 Compare Datasets:學會比對兩組 Dataset,精準抓出「新增 (Added)」、「更新 (Updated)」與「刪除 (Deleted)」的資料。
- 建立同步流程的架構觀念。
核心觀念 (Concepts)
為什麼不自己寫 IF 判斷?
手動比對大量 Item 需要巢狀迴圈(「這筆 key 在另一邊存不存在?」「對應欄位有沒有改?」),工作流會變得龐大且慢。Compare Datasets 在底層優化比對邏輯,適合處理成千上萬筆的差異同步。
四個輸出分支 (Outputs)
節點依比對結果將 Item 送到四個出口(介面名稱:In A only / Same / Different / In B only): 1. Same (Kept):兩邊都有且內容相同,通常不需再處理。 2. In A only (Added):僅 Input 1 有,代表需執行 Create(如 CRM 新增聯絡人)。 3. Different (Updated):兩邊都有此 key 但內容不同,代表需執行 Update。 4. In B only (Deleted):僅 Input 2 有,代表在來源已不存在,需執行 Delete 或 Deactivate。
TIP
Input 1 = 來源/最新(如剛匯出的名單),Input 2 = 目標/現有(如資料庫目前狀態)。接反時 In A only 與 In B only 的語義會對調。
節點配置 (Node Setup)
Compare Datasets Node
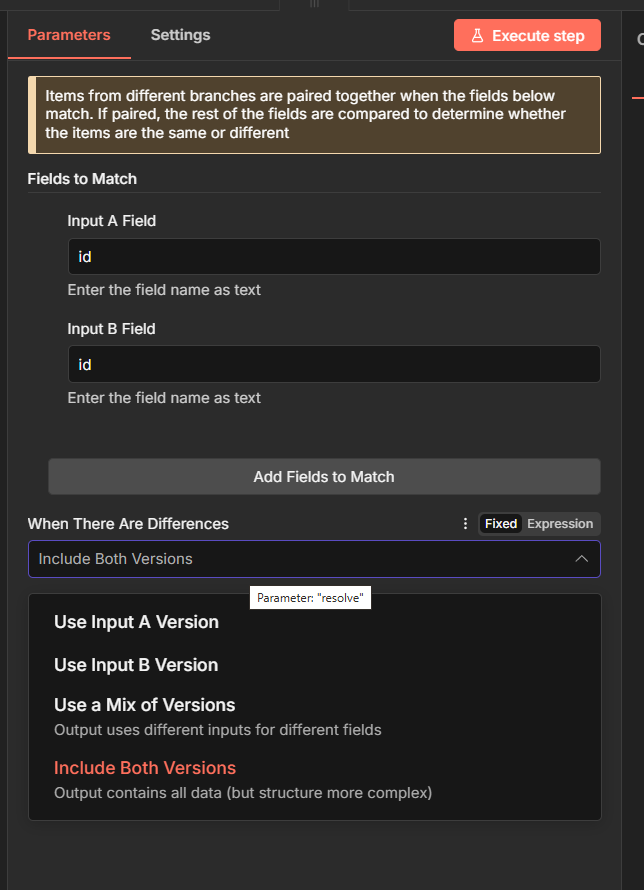
- Fields to Match:用來認定「同一筆 Item」的欄位(Primary Key),兩輸入依此欄位值配對。通常設
id或email;可 Add Fields to Match 支援多欄。比對時先依此欄位找對應,再比較其餘欄位是否相同。 - When There Are Differences:當兩邊都有同一 key 但內容不同時,輸出的 Different 分支要採用哪一側的欄位值。
- Prefer Input A Version 差異時以B輸入為準。
- Prefer Input B Version:差異時以B輸入為準。
- Use a Mix of Versions:可指定部分欄位從 Input A、其餘從 Input B;For Everything Except 填入要從另一側取得的欄位(逗號分隔)。
- Include Both Versions:A 和 B 的版本都保留在輸出中
- Options:Fields to Compare 可限制只比較指定欄位(例如只比
score);Fields to Skip Comparing 可排除部分欄位不參與「是否相同」的判斷;Fuzzy Compare 開啟時會容忍型別差異(如數字3與字串"3"視為相同);Disable Dot Notation 可關閉parent.child欄位路徑;Multiple Matches 可選 Include All Matches 或 Include First Match Only(重複 key 時只保留第一筆)。
節點固定輸出四個分支:In A only(僅 Input 1 有,對應新增)、Same(兩邊相同)、Different(兩邊都有但內容不同,對應更新)、In B only(僅 Input 2 有,對應刪除/缺失)。
專業操作 (Action)
Step 1: 準備新舊資料庫 (Mock)
我們來模擬系統同步的核心情境。
1. Input 1 (最新名單):包含 Danny (ID: 1, 評分: 100)、Amy (ID: 2, 評分: 80)。
2. Input 2 (舊名單庫):包含 Danny (ID: 1, 評分: 90)、Bob (ID: 3, 評分: 50)。
Step 2: 設定 Compare Datasets
- 把 Input 1 跟 Input 2 接上
Compare Datasets節點。 - Fields to Match 設為
id(以 id 認定同一筆 Item)。 - 這份範例在 Options 使用 Fields to Compare =
score,代表只比較分數欄位;name不參與差異判斷。 - 點擊 Execute Workflow。
Step 3: 觀察四個輸出分支
切換節點各輸出分支檢視結果:
- In A only (Added):Amy(Input 2 沒有 id 2)。
- Different (Updated):Danny(id 相同,score 由 90 變 100)。
- In B only (Deleted):Bob(Input 1 已無 id 3)。
- Same (Kept):無(本例沒有兩邊完全一致的 Item)。
後續可依四個分支分別接「新增 API」、「更新 API」、「刪除 API」,即可組成雙向同步流程。
實戰挑戰 (Challenge)
- 選擇性更新:若 Input 1 某筆 Item 少了
phone欄位而 Input 2 有,會落在 Different 分支。在 When There Are Differences 選 Use a Mix of Versions,並用 For Everything Except 指定要從 Input 2 補上的欄位(如phone),輸出的 Item 就會合併兩側欄位。
範例 (Example)
下面的工作流來觀察這個新舊資料比對的分類結果。這份範例以 id 做配對鍵,並只比較 score 欄位,方便先理解 Added / Different / In B only 的分流邏輯。